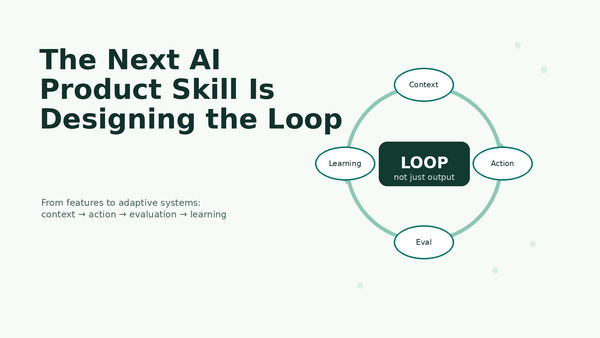
When Compute Becomes Product Strategy
Why the future of AI products is not one giant model everywhere, but a hybrid intelligence stack of frontier models, SLMs, open models, routing, and evals.


Anthropic’s new SpaceX compute deal looks, at first, like a capacity announcement. More GPUs. Higher Claude Code limits. Better API throughput. Fewer moments where serious users run into the invisible wall of scarcity.
That read is true, but incomplete.
The more important signal is that compute is becoming product strategy. Not just an infrastructure moat for frontier labs, and not just the hidden substrate behind model training. Compute is now shaping the visible product experience: how long agents can run, how much context a user can bring, whether the product slows down during peak demand, whether a team can trust AI inside real work, and what kind of pricing a company can safely promise.
Anthropic said it had signed an agreement to use all of the compute capacity at SpaceX’s Colossus 1 data center, adding more than 300 megawatts and over 220,000 NVIDIA GPUs within the month. The same announcement translated that capacity directly into product changes: doubled Claude Code five-hour limits for Pro, Max, Team, and seat-based Enterprise plans; removal of peak-hour reductions for Pro and Max; and higher Opus API rate limits.
That is the part PMs should pay attention to. The infrastructure announcement immediately became a product announcement.
But the conclusion is not “everyone needs more frontier compute.” That is only half the story. The better conclusion is that AI products now need an intelligence architecture: a deliberate way to decide which tasks deserve expensive frontier models, which tasks should run on smaller models, where open-source or open-weight models make more sense, and how to route work across the stack.
The winning AI products will not simply use the biggest model everywhere. They will use the right intelligence in the right place — and they will make that routing invisible to the user.
The old AI product assumption is breaking
The first phase of generative AI product building had a simple default: call the strongest model available, wrap it in a workflow, and optimize later.
That made sense when teams were still proving that the model could do useful work. It made sense when the core product question was, “Can this thing reason, write, code, summarize, or classify well enough to matter?”
But the market is moving into a different phase. OpenAI’s enterprise usage research argues that frontier firms are not just using AI more often; they are using more intelligence per worker and embedding AI more deeply into workflows. OpenAI says firms at the 95th percentile use 3.5x as much intelligence per worker as typical firms, and that the largest gap appears in agentic tools, with frontier firms sending 16x as many Codex messages per worker.
That is a very different demand profile from casual chat.
When AI becomes part of production work, usage compounds. The product is no longer answering isolated prompts. It is reading internal documents, editing code, classifying support tickets, generating test cases, drafting customer responses, analyzing logs, extracting entities, running background research, and coordinating across tools.
Using a frontier model for all of that is usually the wrong architecture.
Some tasks require deep reasoning. Many do not. Some workflows need maximum accuracy and long-horizon planning. Many need fast, cheap, repeatable transformation. Some work should happen in the cloud. Some should happen inside a private VPC, on an edge device, or locally on a laptop or phone.
The “one big model everywhere” assumption breaks under cost, latency, privacy, reliability, data residency, procurement, and control.
Small models are not a downgrade. They are a product choice.
Small language models are often discussed as if they are merely cheaper, weaker versions of large models. That is the wrong frame.